Building Reliable Activity Sync with Strava and Garmin: What We Learned the Hard Way
On paper, integrating Strava and Garmin looks quite civilized.
A user connects an account, activity data arrives, and your application quietly turns that into challenge progress, leaderboard updates, and general sporting satisfaction.
In practice, it is less civilized than that.
Activities arrive late, accounts are connected incorrectly, edits appear after scoring, webhook events go missing, and large groups of perfectly healthy people decide to upload at roughly the same moment before breakfast. At that point, what looked like an integration problem starts behaving more like a systems problem with opinions.
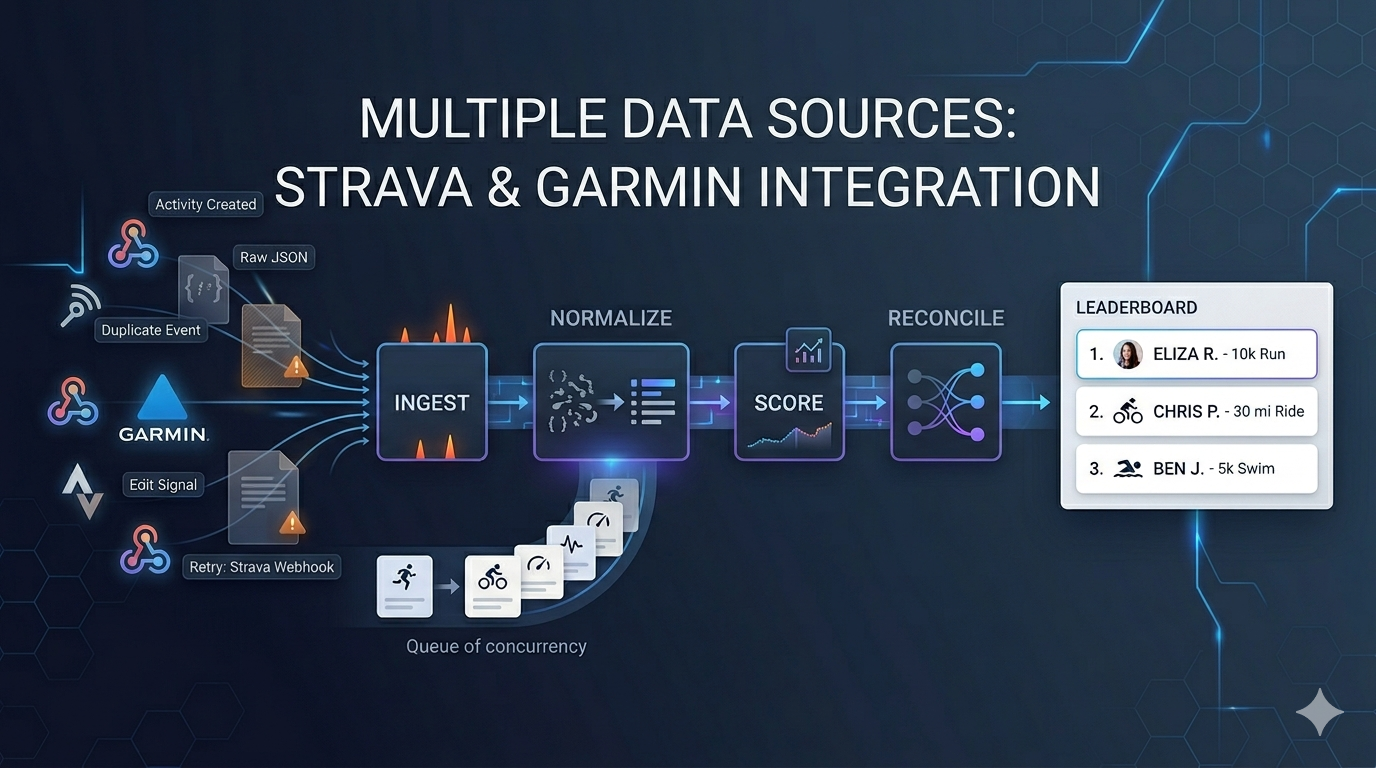
Over time, we learned that reliable fitness-data integration is not really about calling an API. It is about building a pipeline that can tolerate ambiguity, concurrency, corrections, and the occasional provider behaviour that makes perfect sense only after you have spent a week debugging it.
The API Is the Easy Part
The first version of an activity integration usually feels almost suspiciously straightforward.
You connect the provider. You receive the activity. You compute the score. You update the leaderboard.
This works beautifully for a while, which is often how trouble begins.
At low scale, even a tightly coupled design can appear perfectly reasonable. Then challenge rules become more complex, participant numbers rise, provider edge cases appear, and the cheerful little pipeline you built begins to reveal a more dramatic side.
That was one of the first real lessons for us: provider integration is only the front door. The harder work begins after the data gets in.
Strava and Garmin Encourage Very Different Mental Models
If you start with Strava, you tend to think in a fairly familiar API-first way.
Users authorize access, webhook events tell you something happened, and your system fetches and processes updates as needed. That model is not exactly simple, but it is at least recognisable.
Garmin was a surprise.
Coming from Strava, Garmin’s push-oriented approach felt unusual at first. In some respects it was actually easier operationally, which was mildly unsettling. Instead of constantly thinking about what to fetch next, the model nudged us toward receiving and processing provider-delivered updates more cleanly.
That said, Garmin also felt more limited in some important areas.
From our experience, it offered less flexibility around profile data, and the inability to pull historical activity data reduces its usefulness in scenarios where you want to backfill user history, recover older state, or rebuild challenge context after the fact.
So Garmin was simpler in some ways, but only if you were willing to stay within its boundaries. Which, naturally, is where product requirements often become more ambitious.
Users Will Connect the Wrong Strava Account
One of the more practical challenges had nothing to do with architecture and everything to do with human beings being human.
Some users have multiple Strava accounts. Quite a few of them do not immediately notice which one they have connected.
This creates a fun little situation where the integration succeeds, the tokens look fine, the webhook setup appears healthy, and the expected activities never arrive because the user has very efficiently linked the wrong account.
Technically, everything is working. Operationally, everything is not.
We reduced this problem by adding a confirmation step after connection so users could verify that they had linked the account they actually intended to use.
It was a modest product change, but it solved a very real support problem. It was also a useful reminder that reliability is not just about backend correctness. Sometimes it is about preventing an avoidable mistake before it becomes a debugging session.
Webhooks Are Helpful, but Not Holy
Strava webhooks are useful. They are not, however, a sacred and flawless event stream.
That distinction matters.
One of the easiest mistakes is to treat a webhook as the final truth of activity state. In reality, a webhook is better understood as a signal that something changed and you should take a closer look.
That shift in mindset improved our design considerably.
Once you stop assuming that every webhook will arrive exactly once, in order, and with all the consequences you care about, you start building a more durable system. You also become a slightly calmer person.
In practice, we still had to deal with:
- missed webhook events
- activity edits after initial ingestion
- cropped activities
- downstream score changes based on updated activity state
That is why webhook processing alone was never enough.
Cropped Activities and Missed Events Force You to Reconcile
One issue we still had to account for was activity cropping.
We do not reliably get Strava events for cropped activities in a way that fully solves the scoring problem. That means a webhook-driven pipeline, on its own, cannot guarantee that the challenge state remains correct.
The answer was to build a reconciliation pipeline.
That pipeline serves two jobs:
- recover from missed webhook events
- re-check activities whose effective scoring state may have changed after edits or crops
In other words, reconciliation is not merely a disaster-recovery feature. It is part of the normal operating model.
Once we accepted that provider events were not a perfect ledger, the design became much easier to reason about:
- webhooks provide speed
- reconciliation provides correctness
That division of responsibility made the entire system more dependable.
Concurrency Arrives Before You Are Emotionally Ready
A fitness challenge does not produce activity traffic in a polite, evenly distributed fashion.
It arrives in waves, usually at exactly the moment your system would have preferred a quiet cup of tea.
Most athletes complete activities in the early hours of the day, which means uploads cluster heavily in the morning. During an active challenge, that becomes the busiest period in the system. Then you add group rides, group runs, and club sessions, and many participants upload at nearly the same time because they finished at nearly the same time.
From the outside, this looks like healthy engagement.
From the inside, it looks like hundreds of concurrent updates all trying to touch the same challenge state, participant totals, scoring records, and leaderboard calculations at once.
That is the point where optimistic early designs begin to lose their composure.
Concurrency was not an abstract concern for us. It was one of the forces that exposed architectural weaknesses as load increased. The system did not receive one tidy activity at a time. It received bursts of overlapping work against shared challenge state, often concentrated into narrow windows.
If your pipeline is not designed for those bursts, the database will eventually make its views known.
Our First Pipeline Coupled Ingestion and Scoring Too Tightly
Our initial design combined ingestion and scoring in the same path.
When an activity arrived, that same flow tried to store the provider data and immediately compute its challenge impact. At first, this seemed efficient. It was also fine right up until it wasn’t.
As scoring became more sophisticated, especially around:
- multiple activities on the same day
- challenge-specific scoring rules
- edits and corrections after ingestion
- leaderboard recalculations
the amount of contention in that path increased significantly.
Under heavier challenge load, we started seeing a large number of database deadlocks.
The root problem was not merely that the database was under pressure. The issue was that too much responsibility had been placed inside one transactional path. We were asking the same workflow to ingest, interpret, score, and update shared state while many other copies of that workflow were attempting to do the same thing at once.
The database, understandably, objected.
Stability Improved Once We Decoupled the Pipeline
The architecture became much more stable as we split responsibilities apart.
Instead of treating activity arrival and score computation as one operation, we gradually moved toward a more decoupled model:
- ingest provider data
- normalize and persist the activity state
- enqueue downstream work
- compute scoring separately
- reconcile later when needed
That change made a substantial difference.
It reduced coupling between provider delivery and challenge logic. It made retries safer. It gave us room to improve scoring without turning every new rule into a concurrency problem. And it reduced the likelihood that a burst of morning uploads would immediately translate into transactional theatre in the database.
Just as importantly, it clarified an architectural point that is easy to miss early on:
ingestion is not scoring
Provider data tells you what happened on the fitness platform. Scoring logic determines what that means inside your product.
Those should not be the same stage.
Missed Strava Webhook Events Need a Planned Response
At some point, every webhook integration has to answer an awkward question:
What happens when events do not show up?
For us, the answer was to stop treating missed webhook events as exceptional and start designing for them directly.
Our practical approach is:
- use webhooks for near-real-time responsiveness
- store normalized activity state rather than trusting transient payloads
- run reconciliation jobs that re-check activities likely to have changed
- allow scoring to be recomputed independently of ingestion
- make processing idempotent so retries are safe
That gives us two layers of reliability:
- webhooks for speed
- reconciliation for correctness
It is not quite as elegant as pretending event delivery is perfect, but it is far more useful.
What We Would Do Earlier If Starting Again
If we were building the integration again from scratch, we would adopt a few principles much earlier:
- treat webhooks as change signals, not final truth
- build reconciliation from the beginning
- separate ingestion, normalization, and scoring into distinct stages
- design every provider-processing path to be idempotent
- expect concurrency spikes, not smooth traffic
- assume some users will connect the wrong account unless the product helps them verify
- expect scoring complexity to grow over time
None of these ideas are especially glamorous. They are, however, the sort of decisions that save you from having to explain deadlocks at inconvenient times.
Final Thought
The hard part of integrating Strava and Garmin is not getting activity data to flow once.
The hard part is making the system reliable when reality becomes untidy.
Users connect the wrong account. Activities get edited. Webhook events go missing. Some provider behaviours are simpler than expected. Others are more limited than you would prefer. And the moment challenge scoring becomes more sophisticated, concurrency and architecture matter far more than the API client itself.
That was the biggest lesson for us.
Reliable activity sync is not just an integration task. It is an architecture task with a strong opinion about separation of concerns.